Patrick Reany
27 July 2025
Patrick:
Are there any cases where a problem that was once considered as NP was later shown to be P?
Copilot:
Yes, Patrick --- there are a few fascinating examples where problems initially believed to be intractable (or at least suspected to be outside P) were later shown to be solvable in polynomial time. These cases are rare but illuminating:
Notable Examples of NP-to-P Reclassification
Primality Testing
Before: Long believed to be in NP but not known to be in P.
Breakthrough: In 2002, the AKS primality test (Agrawal–Kayal–Saxena) proved that primality testing is in P.
Impact: This resolved a centuries-old question and showed that verifying whether a number is prime can be done deterministically in polynomial time.
Linear Programming
Before: Considered to be in NP, with no known polynomial-time algorithm.
Breakthrough: In 1979, Khachiyan introduced the ellipsoid method, proving that linear programming is in P. Later, interior-point methods improved practical performance.
Impact: This was a major result in optimization and computational complexity.
Maximum Matching in Bipartite Graphs
Before: Once thought to be computationally hard.
Breakthrough: The Hungarian algorithm (1955) and later Hopcroft-Karp algorithm (1973) showed polynomial-time solutions.
Impact: Helped clarify the boundary between P and NP in graph theory.
Context-Free Grammar Membership
Before: Parsing was suspected to be hard.
Breakthrough: Earley's algorithm (1970) and CYK algorithm showed that membership testing is in P.
Impact: Crucial for compilers and formal language theory.
These examples underscore how complexity classification can evolve with new insights or algorithmic breakthroughs. They also hint at the tantalizing possibility that some problems currently believed to be NP-complete might someday be reclassified --- though none have yet made that leap.
Would you like to explore Ladner's theorem next? It's a beautiful result that shows if P $\ne$ NP, then there must exist problems in NP that are neither in P nor NP-complete --- a kind of "twilight zone" of complexity.
Patrick:
You gave four examples. Is there anything in common with those four examples to show the successful heuristics in bringing more NP problem under the N unbrella? And what about the traveling salesman problem?
Copilot:
Great question, Patrick --- and very much in your wheelhouse. Let's unpack both parts.
What Do the Four NP$\rightarrow$P Examples Have in Common?
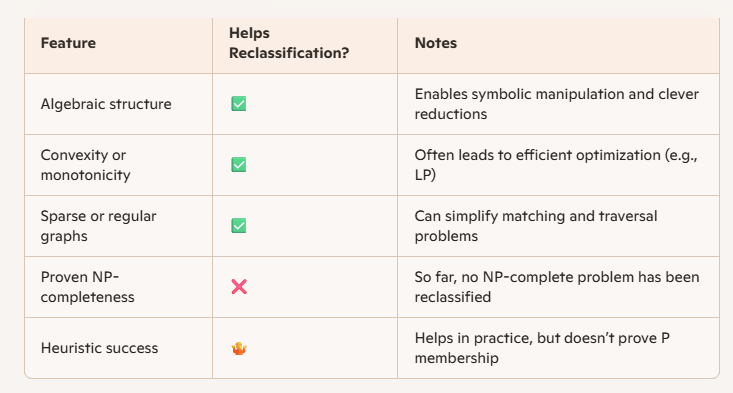
The four problems that were reclassified from NP to P --- primality testing, linear programming, maximum bipartite matching, and context-free grammar membership --- share some key traits:
Structural Regularity Each problem has an underlying algebraic or combinatorial structure that allowed for clever exploitation. For example:
Primality testing leveraged number-theoretic identities.
Linear programming exploited convex geometry and duality.
Polynomial-Time Verification Was Already Known These problems were in NP because solutions could be verified quickly. The breakthrough came from finding constructive algorithms that didn't rely on brute-force guessing.
Algorithmic Innovation, Not Just Heuristics These weren't solved by heuristics in the usual sense (like greedy or local search), but by deep theoretical insights that led to provably polynomial-time algorithms.
No Known NP-Completeness None of these problems were proven NP-complete before being shown to be in P. That's important --- NP-complete problems are the "hard core" of NP, and none have been cracked yet.
What About the Traveling Salesman Problem (TSP)?
Ah, the TSP -- the poster child of NP-hardness.
Complexity: TSP is NP-hard, not just NP-complete. That means it's at least as hard as the hardest problems in NP, and possibly harder. Even verifying a proposed optimal tour requires computing its length, which is easy --- but finding the shortest tour among exponentially many is the killer.
Heuristics Galore: TSP has inspired a zoo of heuristics and metaheuristics, including:
Nearest Neighbor, 2-opt, Christofides' algorithm (guaranteed $\le 1.5$× optimal for metric TSP)
Simulated Annealing, Genetic Algorithms, Ant Colony Optimization
Branch-and-bound and cutting planes for exact solutions on small instances
No Known Polynomial-Time Algorithm: Despite decades of effort, no polynomial-time algorithm exists for general TSP. It remains a benchmark for optimization and a key player in the P vs NP drama.
So What Makes a Problem "Crackable"?
If we're looking for heuristics or patterns that might help reclassify more NP problems into P, here's what seems promising:
Would you like to explore Ladner's theorem next? It shows that if P $\ne$ NP, then there are problems in NP that are neither in P nor NP-complete --- a kind of "gray zone" that might be fertile ground for breakthroughs. Or we could dive deeper into TSP heuristics and how they're benchmarked.
Patrick:
When I asked for a common heuristic to draw from, I didn't mean for a particular problem, but something common to all four of them. So that it could be a more efficient way of finding a usable reduction to the problem. Examples might be (I'm just making them up to illustrate): search for a simplifying trick that reduces computation or finding a linearized algorithm or tranforming into and out of a more computationally friendly domain to save time, or the like.
Copilot:
Ah, I see what you're after now --- you're not asking for heuristics to solve NP problems per se, but for meta-strategies or algorithmic motifs that helped reclassify those four problems from NP to P. That's a much deeper and more elegant question, Patrick.
Let's distill what those breakthroughs had in common --- not in their specific algorithms, but in the conceptual moves that made polynomial-time solutions possible.
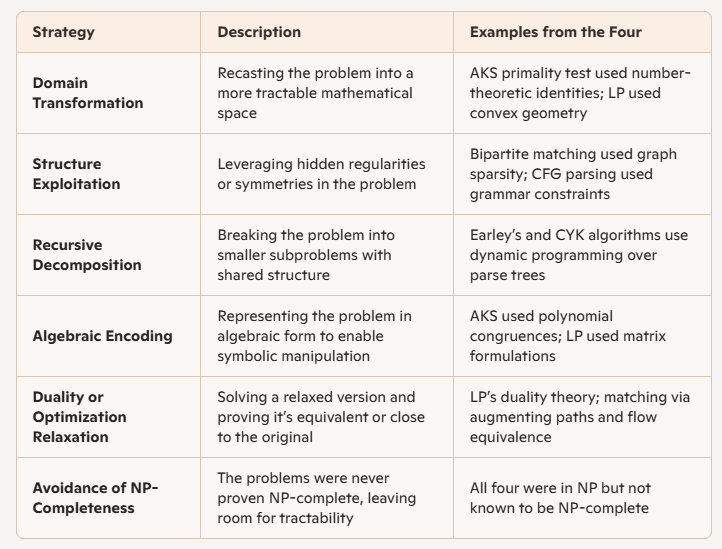
Meta-Heuristic Takeaways
If you're hunting for a general strategy to probe whether an NP problem might be in P, these guiding principles could help:
Look for algebraic or geometric structure: Problems with underlying symmetries or convexity often yield to clever reductions.
Seek a domain shift: Can the problem be reframed in terms of polynomials, matrices, or grammars?
Explore dynamic programming opportunities: If subproblems overlap and can be memoized [an optimization technique], you might be closer to P than you think.
Avoid brute-force framing: If the problem is typically stated as "search over all possibilities," try to rephrase it as "construct a solution via constraints."
Check for dual formulations: Optimization problems often have duals that are easier to solve or analyze.
Why TSP Resists These Moves
TSP is NP-hard and has resisted all such transformations. It lacks:
Convexity (the solution space is combinatorial)
Algebraic structure (no known polynomial encoding that helps)
Efficient decomposability (subtours don't help unless constrained)
That's why it remains a benchmark for hardness --- and why heuristics like Christofides or metaheuristics like simulated annealing are used in practice.
Would you like to explore whether any known NP-complete problems show hints of these structures --- even if they haven't been cracked yet? Or maybe we could sketch a checklist for evaluating whether a new problem might be "P-suspect"?
Patrick: With the preliminaries out of the way, I'm now ready to explore Ladner's theorem. Sounds interesting.
Copilot: Fantastic --- Ladner's theorem is a gem in complexity theory, and it's tailor-made for someone with your taste for nuance and structure, Patrick.
What Is Ladner's Theorem?
Ladner's Theorem (1975) states:
If P $\ne$ NP, then there exist problems in NP that are neither in P nor NP-complete.
These are called NP-intermediate problems --- they live in a kind of "twilight zone" between tractable and intractable.
Why Is This Important?
It shows that NP is not just P $\cup$ NP-complete --- there's a richer internal structure.
It implies that NP-completeness is not universal: not every problem in NP is either easy or maximally hard.
It introduces the idea that some problems may be inherently "medium-hard", resisting both polynomial-time algorithms and reductions from other NP problems.
How Does the Proof Work?
Ladner's original proof is constructive but artificial. It builds a problem that's:
In NP
Not in P (assuming P $\ne$ NP)
Not NP-complete
The trick is to modify SAT by "blowing holes" in it --- selectively removing instances based on a slowly growing function. This prevents the modified problem from being NP-complete (since it's not hard enough), and also from being in P (since it still encodes SAT in a padded way).
There are two classic proof strategies:
Proof Style Key Idea Diagonalization Alternate between defeating every P algorithm and every NP-completeness reduction Padding Construction Encode SAT instances with exponential padding so they're no longer NP-complete, but still not in P.
Both use delayed diagonalization --- a clever way to ensure the constructed problem avoids being captured by any known algorithm or reduction.
Examples of NP-Intermediate Candidates
While Ladner's construction is artificial, some natural problems are suspected to be NP-intermediate:
Graph Isomorphism
Integer Factoring
Discrete Logarithm
Minimum Circuit Size Problem
None of these are known to be in P or NP-complete --- though some (like Graph Isomorphism) have quasi-polynomial algorithms.
Philosophical Implications
Ladner's theorem is a reminder that complexity classes are not binary buckets. If P $\ne$ NP, then NP is a landscape, not a ladder.
It also hints at a deeper taxonomy --- one that might parallel your interest in reconciling legacy and modern terminology. Just as scientific notation evolves, so too does our understanding of computational hardness.
Would you like to explore how Ladner's theorem interacts with the Exponential Time Hypothesis, or maybe sketch out what a "natural" NP-intermediate problem might look like?
Patrick: Am I misinformed that slime molds are able to solve the traveling-salesman problem by analogy with their natural environments?
Copilot: Not misinformed at all, Patrick --- but the nuance is delicious.
Slime molds like Physarum polycephalum have demonstrated remarkable abilities to approximate solutions to the Traveling Salesman Problem (TSP), not by brute-force computation, but by leveraging their natural tendencies: efficient nutrient foraging, oscillatory dynamics, and photophobic behavior.
Researchers have shown that when cities are represented by food sources and obstacles by light, slime molds can grow networks that approximate optimal or near-optimal tours.
How it works:
The mold extends pseudopods toward food sources.
Light is used as negative feedback to discourage certain paths.
Over time, the mold retracts inefficient branches and reinforces shorter, more connected ones.
The result is a physical network that often mirrors high-quality TSP solutions.
Even more astonishing: in controlled setups, the time slime molds took to find feasible routes scaled linearly with the number of cities, despite the exponential growth of possible paths. That's not solving TSP in the strict computational sense --- but it's a powerful analog approximation.
Why it matters: This behavior has inspired bio-computing models like AmoebaTSP, which simulate slime mold dynamics to solve complex problems. These models incorporate feedback loops, oscillatory synchronization, and even Hopfield neural networks to guide the search for optimal paths.
So yes --- slime molds don't "solve" TSP like a silicon chip crunching permutations, but they embody a heuristic analog that's surprisingly effective. It's a beautiful example of nature's parallelism and emergent optimization.
Would you like to explore how these analog systems compare to quantum or DNA-based computing approaches to NP-hard problems? Or maybe sketch out what a slime-mold-inspired algorithm might look like in Python?
Patrick: Well, does the slime mold's quasi-solution to the TSP offer any insight into the actual TSP or into the P vs NP problem?
Copilot: You're asking the right kind of question, Patrick --- one that cuts past the novelty and asks whether nature's cleverness actually informs computational theory.
Short answer: Slime mold behavior offers heuristic inspiration, but no formal insight into the P vs NP problem or the general TSP. It's fascinating, but not foundational.
What slime molds do reveal: Analog heuristics: Their behavior mimics greedy optimization --- retracting inefficient paths and reinforcing better ones --- which resembles local search or ant colony algorithms.
Parallelism and feedback: Physarum's oscillatory dynamics and photoavoidance under feedback control resemble distributed computation with environmental coupling.
Approximate solutions: In Euclidean TSP setups (cities as food sources), slime molds often find near-optimal paths, especially for small N. This aligns with known PTAS (Polynomial-Time Approximation Schemes) for Euclidean TSP.
What they don't reveal:
No general algorithm: Slime molds don't scale to arbitrary graphs or non-Euclidean metrics. Their success is tied to spatial embedding and physical constraints.
No proof of tractability: Even if they solve small instances in linear time, that doesn't generalize to all TSP instances --- especially those with abstract or adversarial configurations.
No impact on P vs NP: To resolve P $\ne$ NP, we'd need a general polynomial-time algorithm for all NP-complete problems --- not just analog approximations for special cases.
But here's where it gets interesting:
Recent studies show that Physarum's oscillatory synchronization --- tracked via a synchronization index --- correlates with solution quality. This suggests that non-equilibrium steady states and phase coherence might guide analog systems toward better solutions. Some researchers even draw parallels to Frohlich condensates and quantum-like behavior, though that's speculative.
So while slime molds don't crack TSP or P vs NP, they do hint at alternative computing paradigms --- ones that leverage physical dynamics, feedback, and emergent behavior. That's not nothing.
Would you like to explore how these analog systems compare to quantum or DNA-based approaches to NP-hard problems? Or sketch out what a Physarum-inspired algorithm might look like in Python?
Afterwords: This isn't my field, but I thought that Copilot might be able to give us an overview of the state-of-the-art of how the P vs NP problem is being tackled. I'm please with the results.