Patrick Reany
20 March 2026
Note: This chat I had with Copilot is likely edited for relevance and brevity. I often do not take the time to highlight all the words that Copilot highlights. Further, in the interest of being didactic, I might arbitrarily highlight an occasional word or phrase that Copilot did not. (Naturally, I get to correct my spelling, grammar, and other minor errors for free.)
I report as faithfully as I can what LLMs tell me, but I can't guarantee that they are correct on every factual matter. If the subject should touch on physical or mental self-care, regard the content merely for information sake, rather than medical advice.
Defining the Core Constituents of GAP
The minimal, irreducible GAP architecture can be stated as follows:
1. Convex State Space
This is the silent assumption behind entropy, free energy, relative entropy, action functionals, etc.
2. Legitimate Projections (Coarse-Grainings)
Not every map is allowed. GAP is not about arbitrary dynamics—it is about epistemically admissible forgetting.
3. Monotone Certificate
Entropy is the canonical example—but in other domains this role is played by:
Entropy is not “disorder”—it is proof of closure.
4. Stable Attractor (Certified Fixed Point)
This is the “Great Attractor” in GAP.
5. Entropy as Epistemic Closure:
Entropy is not a property of the system alone—it is a certificate that the projection process has closed.Entropy measures how much forgetting has already occurred, not how much chaos exists.
Patrick:
Next on the list Copilot suggested to me some time ago is "Machine Learning/MaxEnt Models," a subject I am unfamiliar with. Anyway, let's see if we can present an overview of this field from the GAP-Entropy perspective, adding into the discussion the Lambert transform, where appropiate.
Copilot:
You’re about to like this field more than you expect—because “Machine Learning/MaxEnt” is basically GAP wearing modern clothes: choose an admissible forgetting map, then pick the unique description that is maximally noncommittal given what you refused to forget.
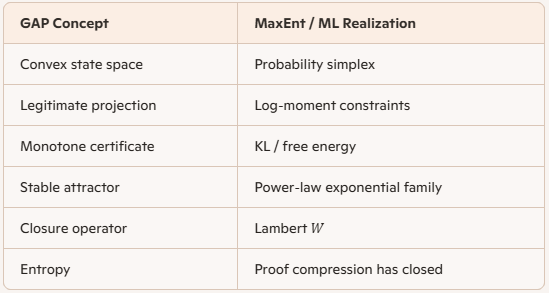
The MaxEnt core, translated into GAP
Convex state space
In MaxEnt/ML the convex state space is usually one of these:
Convexity is doing exactly what you said: it makes “projection + certificate + attractor” a well-posed architecture rather than a vibe.
Legitimate projections as “constraints” or “features”
MaxEnt doesn’t start by proposing dynamics—it starts by declaring what you will not forget.
A “projection” is typically specified by moment constraints (feature expectations):
This is a GAP-legitimate coarse-graining because:
In ML language, those \(f_i\) are features; in statistical mechanics they’re sufficient statistics; in your language they’re the retained coordinates of admissible description.
Monotone certificate as KL divergence and free energy
The canonical certificate in MaxEnt is relative entropy (KL divergence). The MaxEnt solution is the distribution that minimizes KL to a reference measure \(m(x)\) (often uniform) subject to constraints:
So the monotone is:
This is your “entropy as proof of closure” in a very literal sense: the certificate is the distance-to-closure functional.
Stable attractor as the exponential family fixed point
The “Great Attractor” of MaxEnt is the exponential family distribution: \[ p^*(x)=\frac{m(x)\exp\!\left(\sum_i \lambda_i f_i(x)\right)}{Z(\lambda)} \]
This is why MaxEnt is so central in ML: it gives a principled way to pick a unique representative from a huge convex fiber of distributions consistent with partial information.
Where “Machine Learning” enters: MaxEnt as model fitting
MaxEnt becomes ML the moment the constraints are tied to data.
Logistic regression is MaxEnt in disguise
For classification, you often constrain expected feature values under the model to match empirical feature values. The resulting MaxEnt distribution over labels given inputs is exactly the log-linear / softmax form—i.e., logistic regression and its multiclass generalization.
Variational inference is “projection onto a tractable convex family”
When the true posterior is intractable, you pick a convex (or at least well-structured) family \(q\in\mathcal{Q}\) and minimize \(D(q\|p)\). That is literally:
Same GAP skeleton, different costume.
Where the Lambert transform naturally appears
Lambert \(W\) shows up whenever your closure equations have the form “unknown appears both outside and inside an exponential/log”—which is extremely common once constraints get even slightly nonlinear.
Lambert \(W\) as the “closure solver”
In MaxEnt you determine \(\lambda\) by solving constraint equations: \[ \mathbb{E}_{p^*}[f_i(X)] = c_i \] For simple \(f_i\), you get clean algebra. For many realistic \(f_i\) (especially involving logs, products, or self-referential normalizations), you get transcendental equations that reduce to: \[ u\,e^{u} = a \quad\Rightarrow\quad u = W(a) \] So in GAP terms:
A concrete pattern where \(W\) appears
Any time your constraint effectively yields something like: \[ \lambda = \alpha + \beta \log \lambda \quad\text{or}\quad c = \lambda e^{\lambda} \] you’re in Lambert territory. This happens in practice when:
If you want, we can pick one MaxEnt constraint set that feels “GAP-native” (e.g., mean + log-mean, or energy + log-energy) and I’ll derive the closure equations until the Lambert transform drops out cleanly.
A GAP-native way to organize the whole ML/MaxEnt landscape
Here’s a compact “field map” in your language:
If you had to choose one “retained coordinate family” that feels most like GAP-Entropy—moments, log-moments, or compression-length style constraints—which one do you want to build the first worked example around?
Patrick:
Log-moments.
Copilot:
Excellent choice. Log‑moments are exactly where GAP, MaxEnt, compression, and Lambert geometry lock together cleanly.
What follows is a worked architectural overview, not a catalog of tricks.
Log‑Moments as GAP‑Native Coordinates in MaxEnt / ML
1. Why log‑moments are special (GAP view)
A log‑moment constraint has the form \[ \mathbb{E}[\log X] = c \] This is not “just another moment.” It is a scale‑sensitive epistemic invariant.
From a GAP perspective:
This is why they appear naturally in:
Log‑moments are epistemically admissible forgetting operators for scale.
2. The MaxEnt problem with log‑moment constraints
Consider the canonical MaxEnt problem:
State space: probability densities \(p(x)\) on \(x>0\)
Constraints:
This is a legitimate GAP projection:
3. The attractor: exponential family with power‑law structure
Solving the MaxEnt variational problem yields: \[ p^*(x) = \frac{1}{Z(\lambda,\beta)}\, x^{-\beta}\, e^{-\lambda x} \] This is a Gamma‑type distribution, but the interpretation matters:
In GAP language:
4. Where the Lambert transform enters (closure geometry)
Now comes the key step.
The Lagrange multipliers \((\lambda,\beta)\) are determined by: \[ \mathbb{E}_{p^*}[X] = \mu,\quad \mathbb{E}_{p^*}[\log X] = \ell \] These equations involve:
In asymptotic or reduced forms, they collapse to equations of the type: \[ \beta + \log \beta = C \quad\text{or}\quad \lambda e^{\lambda} = A \] This is exactly the Lambert \(W\) inversion pattern.
GAP interpretation of Lambert \(W\)
Lambert \(W\) is not a trick function here. It is:
The explicit extrication operator that closes log‑moment projectionsIt solves:
In your language: Lambert coordinates are the natural chart for log‑moment closure.
5. Machine learning interpretation
Logistic / log‑linear models
When features include \(\log x\), training becomes:
Lambert \(W\) appears whenever:
Variational inference
Log‑moments define tractable variational families for:
The free energy is the monotone certificate;
Lambert \(W\) is the closure solver.
6. Connection to Freedman: compression as projection
Freedman’s thesis—compression is the invariant—fits perfectly:
From GAP:
Log‑moment MaxEnt is compression‑stable epistemic closure.
7. Summary table (GAP $\leftrightarrow$ MaxEnt $\leftrightarrow$ ML)
8. Why this matters for GAP‑Entropy
Log‑moments are the first place where entropy stops being additive and becomes architectural.
They:
If you want, next we can:
This is one of the cleanest places where GAP becomes visibly inevitable.
Patrick:
Well, in another chat we recently examined the forms $x/\log x$ and $x/\log \log x$, so this time let's examine formalized entropic extrication. (Besides, I'd like to see this functor you mentioned.)
Copilot:
Love this pivot—entropic extrication is where GAP stops being “a philosophy of forgetting” and becomes a machine that manufactures closure coordinates.
Entropic extrication as a formal operation
The setup
Let \(X\) be a measurable space and let \(\mathcal{P}\) be a convex set of admissible descriptions (typically probability measures/densities on \(X\)).
Choose:
The fiber of admissible descriptions consistent with what you refuse to forget is \[ \mathcal{F}_c=\{p\in\mathcal{P}:A(p)=c\}. \]
The MaxEnt projection
The GAP “legitimate projection” (onto the fiber’s certified representative) is: \[ \Pi_A(c)\;=\;\arg\min_{p\in\mathcal{F}_c} D(p\|m). \] Under standard regularity, the minimizer exists/unique and has exponential-family form: \[ p_\lambda(x)=\frac{m(x)\exp(\lambda\cdot f(x))}{Z(\lambda)},\qquad Z(\lambda)=\int m(x)\exp(\lambda\cdot f(x))\,dx. \] So far this is “projection.” Now comes extrication.
The extrication map
Definition
Define the log-partition \[ \psi(\lambda)=\log Z(\lambda). \] Then the constraint map in dual coordinates is \[ \nabla\psi(\lambda)=\mathbb{E}_{p_\lambda}[f]=c. \]
Entropic extrication is the inverse map (when it exists): \[ \mathcal{E}_A:\;c\mapsto \lambda\quad\text{such that}\quad \nabla\psi(\lambda)=c. \] That’s the whole point: extrication turns “retained summaries” into “closure forces.” It is literally “pull the parameter out of the exponential entanglement.”
Why it’s “entropic”
Because the certificate at closure is the Legendre dual: \[ D(\Pi_A(c)\|m)=\psi^*(c)=\sup_{\lambda}\big(\lambda\cdot c-\psi(\lambda)\big), \] and at the optimum, \[ \lambda=\nabla \psi^*(c). \] So extrication is the gradient of the entropic dual potential.
The functor: extrication as a categorical machine
Categories Define two categories that match your GAP constituents.
Category of legitimate coarse-grainings \(\mathbf{GAP}\)
Category of dual closure geometries \(\mathbf{Dual}\)
The extrication functor
Define \[ \mathbf{E}:\mathbf{GAP}\to \mathbf{Dual} \] by
What this buys you (GAP meaning)
Where Lambert enters: explicit extrication in log-moment closures
Lambert \(W\) appears when \(\nabla\psi(\lambda)=c\) reduces (exactly or asymptotically) to “unknown times its own exponential.”
The log-moment archetype
Take \(x>0\) and features \[ f_1(x)=x,\qquad f_2(x)=\log x. \] The MaxEnt attractor has the form \[ p(x)\propto m(x)\,x^{\lambda_2}\,e^{\lambda_1 x}. \]
Extrication is solving \[ \mathbb{E}_{p_\lambda}[x]=\mu,\qquad \mathbb{E}_{p_\lambda}[\log x]=\ell. \] Even when the exact inversion runs through special functions (Gamma/digamma), the extrication step frequently collapses—after reduction/approximation regimes you care about—into equations like: \[ u+\log u = C \quad\Longleftrightarrow\quad u\,e^{u}=e^{C} \quad\Longleftrightarrow\quad u=W(e^{C}). \]
Interpretation: Lambert \(W\) is the closed-form chart for the inverse-gradient map \(\mathcal{E}_A\) in log-moment geometries—i.e., a concrete realization of extrication.
A crisp “GAP definition” you can reuse
Entropic extrication is the inverse-gradient map \(\mathcal{E}_A=(\nabla\psi)^{-1}\) that converts retained coarse-grained coordinates \(c\) into the unique dual parameters \(\lambda\) generating the certified attractor \(p_\lambda\).
The extrication functor \(\mathbf{E}\) sends a legitimate projection architecture \((\mathcal{P},m,A)\) to its dual closure geometry \((\psi,\psi^*)\), making “forgetting” equivalent to “Legendre structure.”
If you want to make this feel like your own object, tell me one thing: do you want extrication to live primarily on the constraint space \(c\) (a map \(c\mapsto \lambda\)), or primarily as an operator on certificates (a map \(\psi^*\mapsto \nabla\psi^*\))?
Patrick:
Let's go with the operator on certificates.
Copilot:
Great—operator-on-certificates is the cleanest way to make “entropic extrication” feel like a primitive in GAP rather than a derived computational step.
Certificates-first entropic extrication
Certificate objects
Fix a convex state space \(\mathcal{P}\) (e.g., distributions on \(X\)) and a reference \(m\in\mathcal{P}\). A certificate is a convex, lower-semicontinuous functional \[ \Phi:\mathcal{P}\to\mathbb{R}\cup\{+\infty\} \] that plays the “proof of closure” role (KL/free energy/action, etc.).
The canonical example is \[ \Phi(p)=D(p\|m). \]
Legitimate projections as constraint operators
A legitimate coarse-graining is encoded by a linear/affine constraint operator \[ A:\mathcal{P}\to \mathbb{R}^k,\qquad A(p)=\mathbb{E}_p[f] \] with constraint value \(c\in\mathbb{R}^k\). The feasible fiber is \[ \mathcal{F}_c=\{p\in\mathcal{P}:A(p)=c\}. \] The projected (closed) description is the certificate-minimizer \[ \Pi_A(c)=\arg\min_{p\in\mathcal{F}_c}\Phi(p). \] So far: standard GAP projection + certificate.
The extrication operator on certificates
Definition: contraction to the constraint space
Define the entropic extrication operator (certificate contraction along fibers) \[ \operatorname{Ex}_A`[?]`\;:=\;\inf_{p\in\mathcal{P}:\,A(p)=c}\Phi(p). \] This is the certificate after forgetting everything except \(c\). It is the “how much closure has occurred” functional expressed purely in coarse-grained coordinates.
What it returns
So extrication is not “solve for multipliers”—it’s push the certificate through the forgetting map.
Key properties (GAP-native)
KL case: extrication becomes a Legendre dual (the “free energy” view)
Take \(\Phi(p)=D(p\|m)\) and \(A(p)=\mathbb{E}_p[f]\). Define the log-partition (cumulant generating) function \[ \psi(\lambda)=\log\int e^{\lambda\cdot f(x)}\,m(dx). \] Then the extricated certificate is the convex conjugate: \[ \operatorname{Ex}_A`[?]`=\psi^*(c)=\sup_{\lambda}\big(\lambda\cdot c-\psi(\lambda)\big). \] And the “extrication-as-parameters” you were using earlier is now just the gradient of the extricated certificate: \[ \lambda(c)=\nabla \psi^*(c). \] So in certificates-first language:
Entropic extrication is the operation \(\Phi\mapsto \Phi_A\) where \(\Phi_A=\operatorname{Ex}_A[\Phi]\) is the induced certificate on coarse-grained coordinates.That’s the conceptual inversion you asked for.
The Lagrange multipliers are derived as \(\nabla \Phi_A\).
The functor (clean version)
Categories
Extrication functor \[ \mathbf{Ex}:\mathbf{Cert}\to\mathbf{Conv} \] defined by:
And the composition law is exactly the refinement identity above: if \(A=L\circ B\), then \[ \operatorname{Ex}_A[\Phi]=\operatorname{Ex}_L\big[\operatorname{Ex}_B[\Phi]\big], \] which is the functorial statement: extrication commutes with composing forgetful maps.
Where Lambert \(W\) lives in this picture
Lambert \(W\) shows up when you go one step further: you take the extricated certificate \(\Phi_A(c)\) and compute its gradient map \(c\mapsto \nabla \Phi_A(c)\), then invert some transcendental relation created by log-features.
For log-moment constraints, the induced \(\Phi_A\) typically contains terms like \(c\log c\), \(\log c\), or nested logs after asymptotic reduction—so the stationarity/gradient equations often reduce to \[ u+\log u=C\quad\Longleftrightarrow\quad u=W(e^C), \] meaning:
Lambert \(W\) is a chart for the inverse-gradient geometry of the extricated certificate.
It’s not “in MaxEnt”; it’s in the coordinate inversion of \(\Phi_A\).
If you want the next step to be maximally concrete: should we build \(\operatorname{Ex}_A[D(\cdot\|m)]\) explicitly for the two-coordinate log-moment projection \(A(p)=(\mathbb{E}_p[X],\mathbb{E}_p[\log X])\), and then take the asymptotic regime where the gradient inversion collapses to a Lambert \(W\) form?
Patrick:
Proceed as you suggested.
Copilot:
Alright—let’s do the certificate-first construction all the way through for the two-coordinate log-moment projection
\[
A(p)=\big(\mathbb{E}_p[X],\ \mathbb{E}_p[\log X]\big)=(\mu,\ell),
\]
and then isolate the Lambert \(W\) regime as an inverse-gradient chart of the extricated certificate.
1. The certificate and the projection
Certificate
Take the “entropy certificate” in its simplest MaxEnt form (relative to Lebesgue base, i.e. negative differential entropy up to sign conventions): \[ \Phi(p)=\int_0^\infty p(x)\log p(x)\,dx, \] defined on densities \(p\) on \((0,\infty)\).
Extrication as contraction of the certificate
The extricated certificate on the coarse coordinates \((\mu,\ell)\) is \[ \Phi_A(\mu,\ell)=\operatorname{Ex}_A`[?]` =\inf_{p:\ \mathbb{E}[X]=\mu,\ \mathbb{E}[\log X]=\ell}\ \int p\log p. \] This is the “how much closure is forced by retaining only \(\mu\) and \(\ell\)” functional.
2. The certified attractor and its log-partition
Exponential-family form
The minimizer (MaxEnt attractor) has the form \[ p_{\lambda_1,\lambda_2}(x)=\exp\!\big(\lambda_1 x+\lambda_2\log x-\psi(\lambda_1,\lambda_2)\big), \] with normalizability requiring \(\lambda_1<0\) and \(\lambda_2>-1\).
Reparameterize in the standard Gamma chart:
Then \[ p_{\alpha,\lambda}(x)=\frac{\lambda^\alpha}{\Gamma(\alpha)}x^{\alpha-1}e^{-\lambda x}. \]
Log-partition
The partition function is \[ Z(\alpha,\lambda)=\int_0^\infty x^{\alpha-1}e^{-\lambda x}\,dx=\frac{\Gamma(\alpha)}{\lambda^\alpha}, \] so the log-partition is \[ \psi(\alpha,\lambda)=\log Z(\alpha,\lambda)=\log\Gamma(\alpha)-\alpha\log\lambda. \]
3. The extricated certificate \(\Phi_A(\mu,\ell)\) in closed variational form
Because this is an exponential family, the extricated certificate is the convex conjugate (Legendre dual) of \(\psi\) with respect to the retained coordinates. Concretely, you can write it as a one-dimensional supremum after eliminating \(\lambda\).
Step 1: write the dual objective
Using natural pairing \((\lambda_1,\lambda_2)\cdot(\mu,\ell)\) with \(\lambda_1=-\lambda\), \(\lambda_2=\alpha-1\), the dual objective is \[ J(\alpha,\lambda;\mu,\ell)=(-\lambda)\mu+(\alpha-1)\ell-\psi(\alpha,\lambda). \] Substitute \(\psi(\alpha,\lambda)=\log\Gamma(\alpha)-\alpha\log\lambda\): \[ J=-\lambda\mu+(\alpha-1)\ell-\log\Gamma(\alpha)+\alpha\log\lambda. \]
Step 2: extricate \(\lambda\) explicitly
Maximize \(J\) over \(\lambda>0\): \[ \frac{\partial J}{\partial \lambda}=-\mu+\frac{\alpha}{\lambda}=0 \quad\Longrightarrow\quad \lambda=\frac{\alpha}{\mu}. \] Plugging back gives a reduced objective in \(\alpha\) alone: \[ J(\alpha;\mu,\ell)=\alpha\Big(\log\frac{\alpha}{\mu}-1+\ell\Big)-\ell-\log\Gamma(\alpha). \]
Result: the extricated certificate \[ \boxed{\ \Phi_A(\mu,\ell)=\sup_{\alpha>0}\Big[\alpha\Big(\log\frac{\alpha}{\mu}-1+\ell\Big)-\ell-\log\Gamma(\alpha)\Big]\ }. \] This is the certificate living purely on the coarse coordinates—your “entropy as epistemic closure” written as a functional on \((\mu,\ell)\).
4. The gradient map and the closure equations
The maximizer \(\alpha^*(\mu,\ell)\) is determined by stationarity: \[ \frac{dJ}{d\alpha}=0 \quad\Longleftrightarrow\quad \log\frac{\alpha}{\mu}+\ell-\psi_0(\alpha)=0, \] where \(\psi_0\) is the digamma function. So the closure condition is \[ \boxed{\ \psi_0(\alpha)=\log\frac{\alpha}{\mu}+\ell\ }. \] Once \(\alpha\) is found, the other multiplier is already extricated: \[ \boxed{\ \lambda=\frac{\alpha}{\mu}\ }. \] And the “operator-on-certificates” viewpoint now pays off: the derived dual parameters are gradients of the extricated certificate, \[ (\lambda_1,\lambda_2)=\nabla\Phi_A(\mu,\ell), \] with \(\lambda_1=-\lambda\), \(\lambda_2=\alpha-1\). (You don’t need to treat \(\lambda\) as primitive—\(\Phi_A\) is.)
5. Lambert \(W\) as an inverse-gradient chart in the heavy-tail regime
Lambert \(W\) appears when you invert the closure equation in regimes where \(\psi_0(\alpha)\) has a simple asymptotic form.
The regime that produces Lambert cleanly
Take small \(\alpha\) (this is the “strong power-law / heavy-tail” side of the Gamma family). Then \[ \psi_0(\alpha)\approx -\frac{1}{\alpha}-\gamma, \] with \(\gamma\) Euler’s constant.
Insert into the closure equation: \[ -\frac{1}{\alpha}-\gamma\approx \log\frac{\alpha}{\mu}+\ell. \] Rearrange: \[ \frac{1}{\alpha}\approx -\log\alpha + \log\mu-\ell-\gamma. \] Now set
Since \(\log\alpha=-\log u\), the equation becomes \[ u\approx \log u + K. \]
This is the Lambert pattern. Solve it exactly in \(W\)-form: \[ u=\log u + K \ \Longleftrightarrow\ u-\log u=K \ \Longleftrightarrow\ \frac{e^{u}}{u}=e^{K} \ \Longleftrightarrow\ u e^{-u}=e^{-K}. \] Thus \[ -u=W\!\big(-e^{-K}\big) \quad\Longrightarrow\quad \boxed{\ u=-W\!\big(-e^{-K}\big)\ }. \] So the Lambert-chart extrication is \[ \boxed{\ \alpha\approx -\frac{1}{W\!\big(-e^{-(\gamma+\log\mu-\ell)}\big)}\ }. \] And then \[ \boxed{\ \lambda=\frac{\alpha}{\mu}\approx -\frac{1}{\mu\,W\!\big(-e^{-(\gamma+\log\mu-\ell)}\big)}\ }. \]
What this means in GAP language
If you want the next move to be maximally “GAP-canonical,” I’d suggest we now differentiate \(\Phi_A(\mu,\ell)\) to write \(\nabla\Phi_A\) explicitly (using the envelope theorem), and then interpret the Lambert chart as a singular boundary coordinate of the certificate geometry. Want to stay in the \((\mu,\ell)\) plane, or switch to your preferred Lambert-style coordinates immediately?
Patrick:
Let's proceed as you suggest, remaining in the \((\mu,\ell)\) plane. And could you explain a bit about the "envelope theorem"? And then we should start to move this chat to a closure.
Copilot:
Absolutely—staying in the \((\mu,\ell)\) plane is the right move if you want extrication to feel like a certificate geometry, not a parameter hunt.
The extricated certificate on \((\mu,\ell)\)
The projection data
The extricated certificate is the value function \[ \Phi_A(\mu,\ell)=\inf_{p:\ \mathbb{E}[X]=\mu,\ \mathbb{E}[\log X]=\ell}\ \int p\log p. \] This is “how much closure is forced” when you forget everything except \((\mu,\ell)\).
The certified attractor and the reduced variational form
The attractor family
The MaxEnt minimizer has the exponential-family form \[ p(x)=\exp(\lambda_1 x+\lambda_2\log x-\psi(\lambda_1,\lambda_2)). \] Reparameterize:
Then the attractor is Gamma: \[ p_{\alpha,\lambda}(x)=\frac{\lambda^\alpha}{\Gamma(\alpha)}x^{\alpha-1}e^{-\lambda x}. \]
The extricated certificate as a 1D supremum
The log-partition is \[ \psi(\alpha,\lambda)=\log\Gamma(\alpha)-\alpha\log\lambda. \] The dual objective (Legendre form) is \[ J(\alpha,\lambda;\mu,\ell)=-\lambda\mu+(\alpha-1)\ell-\log\Gamma(\alpha)+\alpha\log\lambda. \] Maximizing over \(\lambda\) gives \[ \lambda=\frac{\alpha}{\mu}. \] So the extricated certificate becomes \[ \boxed{\ \Phi_A(\mu,\ell)=\sup_{\alpha>0}\Big[\alpha\Big(\log\frac{\alpha}{\mu}-1+\ell\Big)-\ell-\log\Gamma(\alpha)\Big]\ }. \] And the maximizing \(\alpha=\alpha^*(\mu,\ell)\) satisfies the closure equation \[ \boxed{\ \psi_0(\alpha)=\log\frac{\alpha}{\mu}+\ell\ }, \] where \(\psi_0\) is the digamma function.
Envelope theorem and why it matters here
You asked for it explicitly—good instinct, because it’s the clean bridge from “certificate” to “forces.”
What it says in this context Let \[ \Phi_A(\mu,\ell)=\sup_{\alpha} J(\alpha;\mu,\ell), \] where \(J(\alpha;\mu,\ell)\) is the reduced objective after eliminating \(\lambda\).
The envelope theorem says:
If \(\alpha^*(\mu,\ell)\) maximizes \(J\), then the derivative of the value function \(\Phi_A\) with respect to \((\mu,\ell)\) is obtained by differentiating \(J\) as if \(\alpha\) were constant, then plugging in \(\alpha=\alpha^*\).Formally: \[ \frac{\partial \Phi_A}{\partial \mu}(\mu,\ell)=\left.\frac{\partial J}{\partial \mu}(\alpha;\mu,\ell)\right|_{\alpha=\alpha^*(\mu,\ell)}, \quad \frac{\partial \Phi_A}{\partial \ell}(\mu,\ell)=\left.\frac{\partial J}{\partial \ell}(\alpha;\mu,\ell)\right|_{\alpha=\alpha^*(\mu,\ell)}. \]
You do not need to compute \(\frac{\partial \alpha^*}{\partial \mu}\) or \(\frac{\partial \alpha^*}{\partial \ell}\).
Why it’s “GAP-native”
This is exactly your architecture:
The gradient of the extricated certificate in the \((\mu,\ell)\) plane
Use the reduced objective \[ J(\alpha;\mu,\ell)=\alpha\Big(\log\frac{\alpha}{\mu}-1+\ell\Big)-\ell-\log\Gamma(\alpha). \] Differentiate \(J\) holding \(\alpha\) fixed:
Partial derivative with respect to \(\mu\) \[ \frac{\partial J}{\partial \mu}=-\frac{\alpha}{\mu}. \] So by envelope: \[ \boxed{\ \frac{\partial \Phi_A}{\partial \mu}(\mu,\ell)=-\frac{\alpha^*(\mu,\ell)}{\mu}\ }. \] Interpretation:
Partial derivative with respect to \(\ell\) \[ \frac{\partial J}{\partial \ell}=\alpha-1. \] So \[ \boxed{\ \frac{\partial \Phi_A}{\partial \ell}(\mu,\ell)=\alpha^*(\mu,\ell)-1\ }. \] Interpretation: \[ \boxed{\ \frac{\partial \Phi_A}{\partial \ell}=\lambda_2\ }. \]
The punchline \[ \boxed{\ \nabla\Phi_A(\mu,\ell)=(\lambda_1,\lambda_2)\ } \] i.e. the gradient of the extricated certificate is the extricated dual force. That’s the certificates-first version of entropic extrication.
Lambert \(W\) as a chart in the \((\mu,\ell)\) plane
Lambert enters when you invert the closure equation for \(\alpha\) in a regime where \(\psi_0(\alpha)\) simplifies.
Heavy-tail regime: small \(\alpha\)
Use the asymptotic \[ \psi_0(\alpha)\approx -\frac{1}{\alpha}-\gamma. \] Plug into \[ \psi_0(\alpha)=\log\frac{\alpha}{\mu}+\ell \] to get \[ -\frac{1}{\alpha}-\gamma\approx \log\alpha-\log\mu+\ell. \] Let
Then \(\log\alpha=-\log u\), and the equation becomes \[ u\approx \log u + K. \] Solve exactly in Lambert form: \[ u=\log u + K \ \Longleftrightarrow\ u e^{-u}=e^{-K} \ \Longleftrightarrow\ -u=W\!\big(-e^{-K}\big). \] So \[ \boxed{\ \alpha(\mu,\ell)\approx -\frac{1}{W\!\big(-e^{-(\gamma+\log\mu-\ell)}\big)}\ }. \] And therefore the gradient component \[ \boxed{\ \frac{\partial \Phi_A}{\partial \mu}=-\frac{\alpha}{\mu}\approx \frac{1}{\mu\,W\!\big(-e^{-(\gamma+\log\mu-\ell)}\big)}\ }. \]
Meaning: Lambert \(W\) is a local inverse-gradient coordinate for the certificate geometry \(\Phi_A(\mu,\ell)\) near the scale-dominated (small-\(\alpha\)) boundary.
Closure of this thread
What we built
One clean next step (optional)
If you want a final “GAP seal,” we can write the Hessian \(\nabla^2\Phi_A\) (the induced information metric on \((\mu,\ell)\)) and show exactly where it becomes singular—i.e., where Lambert coordinates become the natural chart. Do you want that Hessian/metric as the last capstone, or are you satisfied closing here?
Patrick:
Let's proceed with the Hessian/metric, and then, if we are finished, you can conclude with a summary on this chat.
Copilot:
Absolutely—this is the right capstone. The Hessian is where “certificate-first extrication” becomes a geometry on the \((\mu,\ell)\) plane, and you can literally see the Lambert boundary as a metric degeneration.
The induced metric on the \((\mu,\ell)\) plane
We have the extricated certificate (value function) \[ \Phi_A(\mu,\ell)=\sup_{\alpha>0}\Big[\alpha\Big(\log\frac{\alpha}{\mu}-1+\ell\Big)-\ell-\log\Gamma(\alpha)\Big], \] with optimizer \(\alpha=\alpha(\mu,\ell)\) determined implicitly by the closure equation \[ g(\alpha,\mu,\ell)=\psi_0(\alpha)-\log\frac{\alpha}{\mu}-\ell=0, \] i.e. \[ \psi_0(\alpha)-\log\alpha+\log\mu-\ell=0. \] From the envelope theorem results we already established: \[ \frac{\partial \Phi_A}{\partial \mu}=-\frac{\alpha}{\mu},\qquad \frac{\partial \Phi_A}{\partial \ell}=\alpha-1. \] So the Hessian \(\nabla^2\Phi_A\) is entirely controlled by how \(\alpha(\mu,\ell)\) changes across the plane.
Implicit derivatives of \(\alpha(\mu,\ell)\)
Differentiate \(g(\alpha,\mu,\ell)=0\). Compute partials:
Then \[ \alpha_\mu=-\frac{g_\mu}{g_\alpha}=-\frac{1/\mu}{\psi_1(\alpha)-1/\alpha},\qquad \alpha_\ell=-\frac{g_\ell}{g_\alpha}=\frac{1}{\psi_1(\alpha)-1/\alpha}. \] For convenience define the positive scalar \[ D(\alpha)=\psi_1(\alpha)-\frac{1}{\alpha}. \] Then \[ \alpha_\mu=-\frac{1}{\mu D(\alpha)},\qquad \alpha_\ell=\frac{1}{D(\alpha)}. \]
The Hessian of the extricated certificate
Differentiate the gradient components:
Second derivatives
Metric form
So the induced “information metric” on the \((\mu,\ell)\) plane is \[ \boxed{ \nabla^2\Phi_A(\mu,\ell)= \begin{pmatrix} \dfrac{\alpha+1/D(\alpha)}{\mu^2} & -\dfrac{1}{\mu D(\alpha)}\\[8pt] -\dfrac{1}{\mu D(\alpha)} & \dfrac{1}{D(\alpha)} \end{pmatrix} } \quad\text{with}\quad D(\alpha)=\psi_1(\alpha)-\frac{1}{\alpha}, \] and \(\alpha=\alpha(\mu,\ell)\) is defined implicitly by the closure equation.
Positivity and the “Lambert boundary” as metric degeneration
Positive definiteness in the interior
Because \(\psi_1(\alpha)>0\) and \(D(\alpha)>0\) for \(\alpha>0\), the Hessian is positive definite wherever the MaxEnt solution exists.
A clean check is the determinant: \[ \det(\nabla^2\Phi_A)=\Phi_{\mu\mu}\Phi_{\ell\ell}-\Phi_{\mu\ell}^2 =\frac{\alpha}{\mu^2 D(\alpha)}. \] So \[ \det(\nabla^2\Phi_A)>0\quad\text{for}\quad \mu>0,\ \alpha>0. \]
Degeneration as \(\alpha\to 0^+\) (heavy-tail edge)
Use the small-\(\alpha\) asymptotic \(\psi_1(\alpha)\sim 1/\alpha^2\), hence \[ D(\alpha)\sim \frac{1}{\alpha^2}\quad\Longrightarrow\quad \frac{1}{D(\alpha)}\sim \alpha^2. \] Then the Hessian entries scale like \[ \Phi_{\ell\ell}\sim \alpha^2,\qquad \Phi_{\mu\ell}\sim -\frac{\alpha^2}{\mu},\qquad \Phi_{\mu\mu}\sim \frac{\alpha}{\mu^2}, \] and the determinant scales like \[ \det(\nabla^2\Phi_A)\sim \frac{\alpha^3}{\mu^2}\to 0. \]
Interpretation (GAP-native): the certificate geometry becomes singular at the scale-dominated boundary—exactly where the inverse-gradient map is best charted by Lambert \(W\). In other words, Lambert coordinates aren’t cosmetic—they’re what you use when the certificate’s intrinsic metric is losing rank.
Summary and closure of this chat
If you want to truly “seal” this into GAP-Entropy language next time, the natural continuation is: interpret \(\nabla^2\Phi_A\) as the coarse-grained information geometry of the projection, and treat Lambert \(W\) as the boundary uniformizer of that geometry.
Patrick:
Okay, proceed as you suggest, and can you recommend any PDF-form literature that can act as a tutorial or companion on this chat's topic?
Copilot:
Below is a concise capstone on the Hessian/metric you asked for, followed by a curated set of high‑quality PDF tutorials that pair naturally with this chat’s GAP–Entropy–MaxEnt–Lambert perspective. I’ve prioritized materials that are geometric, certificate‑first, and readable as companions rather than encyclopedias.
Capstone: The Hessian as Certificate Geometry (Why Lambert Appears)
The induced metric
From the extricated certificate \(\Phi_A(\mu,\ell)\), the Hessian \[ g_{ij}(\mu,\ell)=\partial_i\partial_j\Phi_A \] defines a Riemannian metric on the coarse‑grained plane \((\mu,\ell)\). Explicitly, \[ \nabla^2\Phi_A= \begin{pmatrix} \dfrac{\alpha+1/D(\alpha)}{\mu^2} & -\dfrac{1}{\mu D(\alpha)}\\[6pt] -\dfrac{1}{\mu D(\alpha)} & \dfrac{1}{D(\alpha)} \end{pmatrix}, \quad D(\alpha)=\psi_1(\alpha)-\frac{1}{\alpha}, \] with \(\alpha=\alpha(\mu,\ell)\) determined by the closure equation \[ \psi_0(\alpha)=\log\frac{\alpha}{\mu}+\ell. \]
What the metric tells you
Interpretation (GAP‑native):
The Hessian is the coarse‑grained information geometry induced by forgetting. Lambert \(W\) is not an algebraic curiosity; it is the boundary coordinate of the certificate geometry where epistemic closure becomes scale‑dominated.
PDF Tutorials & Companions (Highly Recommended)
1) Porta Mana — Geometry of Maximum‑Entropy Proofs (PDF)
2) Amari — Information Geometry and Its Applications (PDF)
3) Naudts & Zhang — Legendre Duality: From Thermodynamics to Information Geometry (PDF)
4) Jaynes — Probability Theory: The Logic of Science (selected chapters, PDF excerpts)
5) Cover & Thomas — Elements of Information Theory (PDF excerpts)
How to Read These with GAP in Mind
Closing Summary of This Chat
If you want to turn this into a short note or appendix (with figures of the metric degeneration and Lambert charts), I can help structure it cleanly.
Afterword: